
To reverse engineer a mathematical concept ...

We need to reverse engineer mathematical concepts and code the reverse engineered steps as opposed to the analysed mathematical model to achieve true AI. To be crystal clear of the difference between the two:
If we take, f(x) = x2, when we vary 'x' we are creating a 'possibility space' that comprises of the results of the computation. But, once 'x' is selected as a specific value(s), the outcome computed by the equation drives the analysis into a "different possibility space", which is represented by a totally different equation. It could have become f(y)=y3 for one value of 'x' and f(y) = y4 for another value of 'x'. When we create a mathematical model based on only one observed 'x', we limit ourselves to only that one possibility of 'x', which makes the model static.
Let us take an easily understandable example: Say we write the entrance exam for engineering. The "possibilities space" comprises of ("pass", "not pass"). The instant the choice of "pass" has been selected, the "possibility space" has shifted to the different ranking we get, which is a sequence of numbers, but if the choice is "not pass", the "possibility space" becomes ("re-write", "ask for re-evaluation"...). The two "possibility spaces" are completely different. Again, the instant, the choices were made as pass -> rank is "65", the "possibility space" has shifted to the choice of various engineering fields available to be chosen. And so on, it goes from one "possibility space" to the next, fanning out.
There are two ways to look at this sequence of "possibility spaces". From the perspective of the final outcome, i.e., the engineering field we choose at the end, in which case we identify variables, constants, classifications etc to form a model. Or from the perspective of choice made at each step. One choice of sequence is exam -> result -> rank -> choices of engineering fields -> the final choice, the other could be exam -> result -> reevaluate -> result -> rank -> choice of engineering fields -> final choice. Both resulting in the same outcome.
When we look at it from the first perspective i.e, the final outcome and create a mathematical model, based on the different variables that play a role, we get what we currently do for AI. In this scenario, we look at the final outcome, evaluate the variables that contributed to the outcome and create a model that we hope will work for all the outcomes and all paths. But, this always results in a static model that is highly predictable and ends up being tied to the path of the data from which the model was created. The path that leads to the model is static because we created the model from that path and hence does not change. This gives the gaffes that we usually see with AI where common sense analysis are not handled.
In the second perspective, i.e., choice made at each step, we are not mathematically modelling the outcome, we are reverse engineering the generated mathematical model of the final outcome, understanding the various steps involved and mimicking the logic of the steps. This allows for each step to take a different decision and hence, the unpredictability, the real-time analysis and everything starts playing a role. The higher the resolution of the steps we code, the higher the resemblance it will have to reality. Further, the resolution can go all the way from a coarse analysis to the finest, giving us the required depth of knowledge which is lacking in the traditional mathematical models. In such an approach we can arrive at the final outcome via various different choices, which implies that the paths followed to get the same final model also can vary, which makes it dynamic in nature. The coarser the step, the reaction will be slower, finer the step, the reaction will be responsive.
Reverse engineering the mathematical model means to find out the steps that led to the final mathematical model and made itself visible as the one we model with the variables and constraints that we have made it depend on. For example in the below, if we model the last step, we only consider that outcome and not the steps by which it arrived at that outcome.
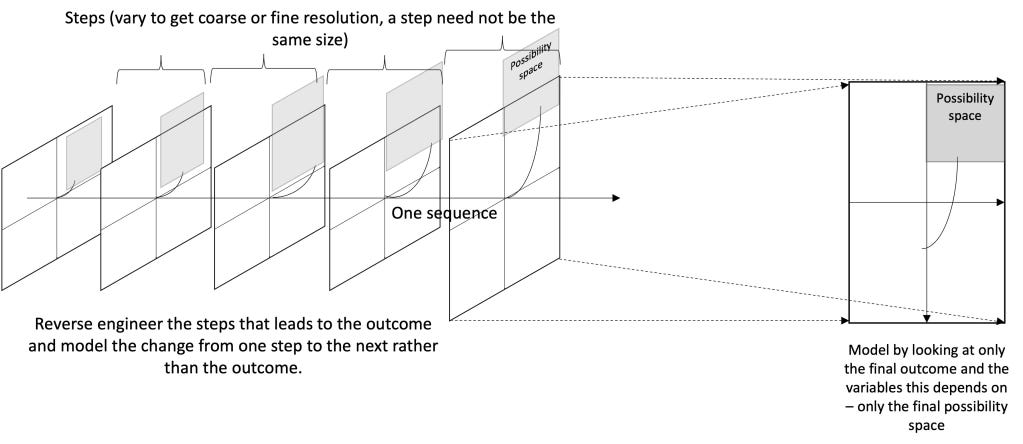
The above can be seen as one sequence that leads to a final result with its own series of possibility spaces that varied as one possibility kept getting picked. So, any point in the possibility space of all the previous steps should have led us to the final outcome. It could also have varied the number of steps that it took to arrive at the final outcome and had variance in the step lengths.
So, the question to ask is "How to reverse engineer a mathematical concept?" The first and simplest need to do this is to remove all assumptions.The problem I have found is that we tend to make many assumptions, left right and centre, without realising it.
Taking the very primary mathematical concept: numbers. All of us know there are "numbers". But, have we ever asked ourselves what a number really is? The assumptions we make to understand numbers are: "we can recognise individual something" and "we know similar individual somethings". For example in the above picture, we already recognise the individual points to come together to form the black arc in a background of white square. Hence we model that arc. We do not realise that it is an indistinct space first: from which we create the points; associate properties of colour to them; distinguish the various colours; recognise similar property points; group them; associate a meaning to the aggregate and hence observe them as a line with certain maths properties. This process is very important to understand and code for true AI.
The start point for any logic should be an indistinct expanse as presented to the brain where nothing is recognised. It is same to seeing a blob of junk printed when we do "cat" of an executable file. We have no clue what is what, it is just a series of indistinct something which we cannot understand. The logic needs to start from the indistinct till we recognise it as individual pieces, understand similarity and count the similar pieces. Only then the logic is complete. To start at a model and recognise that model in the set of data restricts the possibilities of the data set.
The first step to reverse engineering anything is to identify and understand the principles of operation. For this, we need to identify the principles that dictate the steps that give us the recognition of a mathematical model in a data set. In my view there are three principles that dictate this:
The first and foremost principle is "the steps need to be so simple, generic and adaptable that they can be applied from a very small data set to a very large data set and the outcome should appropriately scale and be describable, so that it can grow." When we look at an indistinct blob of data, if the algorithm was so complex that it needed a specific large data size before it forms an understandable concept, then it could not have grown at all. Each and every step of the growth must have been understandable for the latest understandable concept to be formed. It is just that we did not describe it in a mathematical form. For example, the two very coarse steps are, we understand the concept of numbers and counting, before we understand the concept of variables and algebra. But, each of them are describable by themselves and applicable from the smallest to the largest data-set.
The next principle is the steps that we identify has to be as applicable to a static data set to a stream of data, which implies that the algorithm that dictates the steps has to be incremental or accumulative in nature and thus should be recursive in nature. When applied to a static data-set it gives us a static result and when applied to a stream it should give us a stream of resultant data. Currently we think that only statistical mathematical functions can be applied in real-time to stream data. But, is this so?
The final necessity is given that it is recursive in nature, there needs to be a point where the recursion does not generate any noticeable change in the outcome or have established a regular sequence of outcome and hence it takes on a stable mathematical model we observe and create a model with. This point, is the point of equilibrium, which if we find as we are applying to a stream of data, we will end up with the static model that we try to learn.
Using these principles, now we can start reverse engineering the various concepts..